

 Дипломная работа: Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
Дипломная работа: Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
3.1.1 Архитектура сети
Промоделированная архитектура слоя Кохонена в MATLAB NNT показана на рисунке 3.1.
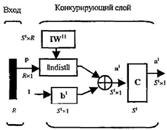
Рисунок 3.1 – Архитектура слоя Кохонена
Нетрудно убедиться, что это слой конкурирующего типа,
поскольку в нем применена конкурирующая функция активации. Кроме того,
архитектура этого слоя очень напоминает архитектуру скрытого слоя радиальной
базисной сети. Здесь использован блок ndist для вычисления отрицательного
евклидова расстояния между вектором входа ![]() и строками матрицы весов
и строками матрицы весов ![]() . Вход функции
активации
. Вход функции
активации ![]() -
это результат суммирования вычисленного расстояния с вектором смещения
-
это результат суммирования вычисленного расстояния с вектором смещения ![]() . Если все
смещения нулевые, максимальное значение
. Если все
смещения нулевые, максимальное значение ![]() не может превышать 0. Нулевое
значение
не может превышать 0. Нулевое
значение ![]() возможно
только, когда вектор входа
возможно
только, когда вектор входа ![]() оказывается равным вектору веса
одного из нейронов. Если смещения отличны от 0, то возможны и положительные
значения для элементов вектора
оказывается равным вектору веса
одного из нейронов. Если смещения отличны от 0, то возможны и положительные
значения для элементов вектора ![]() .
.
Конкурирующая функция активации анализирует значения
элементов вектора ![]() и формирует выходы нейронов,
равные 0 для всех нейронов, кроме одного нейрона-победителя, имеющего на входе
максимальное значение. Таким образом, вектор выхода слоя
и формирует выходы нейронов,
равные 0 для всех нейронов, кроме одного нейрона-победителя, имеющего на входе
максимальное значение. Таким образом, вектор выхода слоя ![]() имеет единственный
элемент, равный 1, который соответствует нейрону-победителю, а остальные равны
0. Такая активационная характеристика может быть описана следующим образом;
имеет единственный
элемент, равный 1, который соответствует нейрону-победителю, а остальные равны
0. Такая активационная характеристика может быть описана следующим образом;
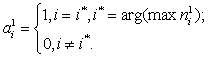 (3.1)
(3.1)
Заметим, что эта активационная характеристика
устанавливается не на отдельный нейрон, а на слой. Поэтому такая активационная
характеристика и получила название конкурирующей. Номер активного нейрона ![]() определяет ту
группу (кластер), к которой наиболее близок входной вектор.
определяет ту
группу (кластер), к которой наиболее близок входной вектор.
3.1.2 Создание сети
Для формирования слоя Кохонена предназначена М-функция newc. Покажем, как она работает, на простом примере. Предположим, что задан массив из четырех двухэлементных векторов, которые надо разделить на 2 класса:
р = [.1 .8 .1 .9; .2 .9 .1 .8]
р =
0.1000 0.8000 0.1000 0.9000
0.2000 0.9000 0.1000 0.8000.
В этом примере нетрудно видеть, что 2 вектора расположены вблизи точки (0,0) и 2 вектора - вблизи точки (1,1). Сформируем слой Кохонена с двумя нейронами для анализа двухэлементных векторов входа с диапазоном значений от 0 до 1:
net = newc([0 1; 0 1],2).
Первый аргумент указывает диапазон входных значений, второй определяет количество нейронов в слое. Начальные значения элементов матрицы весов задаются как среднее максимального и минимального значений, т. е. в центре интервала входных значений; это реализуется по умолчанию с помощью М-функции midpoint при создании сети. Убедимся, что это действительно так:
wts = net.IW{l,l}
wts =
0.5000 0.5000
0.5000 0.5000.
Определим характеристики слоя Кохонена:
net.layers{1}
ans =
dimensions: 2
distanсeFcn: 'dist'
distances:[2x2 double]
initFcn:' initwb '
netinputFcn:'netsum'
positions:[0 1]
size:2
topologyFcn:'hextop'
transferFcn:'compet'
userdata:[1x1 struct].
Из этого описания следует, что сеть использует функцию евклидова расстояния dist, функцию инициализации initwb, функцию обработки входов netsum, функцию активации compet и функцию описания топологии hextop.
Характеристики смещений следующие:
net.biases{1}
ans =
initFcn:'initcon'
learn:1
learnFcn:'learncon'
learnParam:[1x1 struct]
size:2
userdata:[1x1 struct].
Смещения задаются функцией initcon и для инициализированной сети равны
net.b{l}
ans =
5.4366
5.4366.
Функцией настройки смещений является функция lеаrcon, обеспечивающая настройку с учетом параметра активности нейронов.
Элементы структурной схемы слоя Кохонена показаны на рисунке 3.2, а-б и могут быть получены с помощью оператора:
gensim(net)
Они наглядно поясняют архитектуру и функции, используемые при построении слоя Кохонена.
Теперь, когда сформирована самоорганизующаяся
нейронная сеть, требуется обучить сеть решению задачи кластеризации данных.
Напомним, что каждый нейрон блока compet конкурирует за право ответить на
вектор входа ![]() . Если все смещения равны 0, то
нейрон с вектором веса, самым близким к вектору входа
. Если все смещения равны 0, то
нейрон с вектором веса, самым близким к вектору входа ![]() , выигрывает конкуренцию и
возвращает на выходе значение 1; все другие нейроны возвращают значение 0.
, выигрывает конкуренцию и
возвращает на выходе значение 1; все другие нейроны возвращают значение 0.
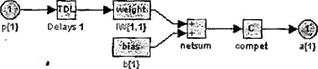
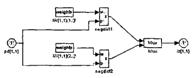
а б
Рисунок 3.2 – Элементы структурной схемы слоя Кохонена
3.1.3 Правило обучения слоя Кохонена
Правило обучения слоя Кохонена, называемое также
правилом Кохонена, заключается в том, чтобы настроить нужным образом элементы
матрицы весов. Предположим, что нейрон ![]() победил при подаче входа
победил при подаче входа ![]() на шаге
самообучения
на шаге
самообучения ![]() , тогда строка
, тогда строка ![]() матрицы весов
корректируется в соответствии с правилом Кохонена следующим образом:
матрицы весов
корректируется в соответствии с правилом Кохонена следующим образом:
![]() . (3.2)
. (3.2)
Правило Кохонена представляет собой рекуррентное
соотношение, которое обеспечивает коррекцию строки ![]() матрицы весов добавлением
взвешенной разности вектора входа и значения строки на предыдущем шаге. Таким
образом, вектор веса, наиболее близкий к вектору входа, модифицируется так,
чтобы расстояние между ними стало еще меньше. Результат такого обучения будет
заключаться в том, что победивший нейрон, вероятно, выиграет конкуренцию и в
том случае, когда будет представлен новый входной вектор, близкий к
предыдущему, и его победа менее вероятна, когда будет представлен вектор,
существенно отличающийся от предыдущего. Когда на вход сети поступает все
большее и большее число векторов, нейрон, являющийся ближайшим, снова
корректирует свой весовой вектор. В конечном счете, если в слое имеется
достаточное количество нейронов, то каждая группа близких векторов окажется
связанной с одним из нейронов слоем. В этом и заключается свойство
самоорганизации слоя Кохонена.
матрицы весов добавлением
взвешенной разности вектора входа и значения строки на предыдущем шаге. Таким
образом, вектор веса, наиболее близкий к вектору входа, модифицируется так,
чтобы расстояние между ними стало еще меньше. Результат такого обучения будет
заключаться в том, что победивший нейрон, вероятно, выиграет конкуренцию и в
том случае, когда будет представлен новый входной вектор, близкий к
предыдущему, и его победа менее вероятна, когда будет представлен вектор,
существенно отличающийся от предыдущего. Когда на вход сети поступает все
большее и большее число векторов, нейрон, являющийся ближайшим, снова
корректирует свой весовой вектор. В конечном счете, если в слое имеется
достаточное количество нейронов, то каждая группа близких векторов окажется
связанной с одним из нейронов слоем. В этом и заключается свойство
самоорганизации слоя Кохонена.
Настройка параметров сети по правилу Кохонена реализована в виде М-функции learnk.
3.1.4 Правило настройки смещений
Одно из ограничений всякого конкурирующего слоя состоит в том, что некоторые нейроны оказываются незадействованными. Это проявляется в том, что нейроны, имеющие начальные весовые векторы, значительно удаленные от векторов входа, никогда не выигрывают конкуренции, независимо от того как долго продолжается обучение. В результате оказывается, что такие векторы не используются при обучении и соответствующие нейроны никогда не оказываются победителями. Такие нейроны-неудачники называются "мертвыми" нейронами, поскольку они не выполняют никакой полезной функции. Чтобы исключить такую ситуацию и сделать нейроны чувствительными к поступающим на вход векторам, используются смещения, которые позволяют нейрону стать конкурентным с нейронами-победителями. Этому способствует положительное смещение, которое добавляется к отрицательному расстоянию удаленного нейрона.
Соответствующее правило настройки, учитывающее нечувствительность мертвых нейронов, реализовано в виде М-функции learncon и заключается в следующем - в начале процедуры настройки всем нейронам конкурирующего слоя присваивается одинаковый параметр активности:
 , (3.3)
, (3.3)
где ![]() - количество нейронов
конкурирующего слоя, равное числу кластеров. В процессе настройки М-функция
learncon корректирует этот параметр таким образом, чтобы его значения для
активных нейронов становились больше, а для неактивных нейронов меньше.
Соответствующая формула для вектора приращений параметров активности выглядит
следующим образом:
- количество нейронов
конкурирующего слоя, равное числу кластеров. В процессе настройки М-функция
learncon корректирует этот параметр таким образом, чтобы его значения для
активных нейронов становились больше, а для неактивных нейронов меньше.
Соответствующая формула для вектора приращений параметров активности выглядит
следующим образом:
![]() , (3.4)
, (3.4)
где ![]() - параметр скорости настройки;
- параметр скорости настройки; ![]() -вектор,
элемент
-вектор,
элемент ![]() которого
равен 1, а остальные - 0.
которого
равен 1, а остальные - 0.
Нетрудно убедиться, что для всех нейронов, кроме нейрона-победителя, приращения отрицательны. Поскольку параметры активности связаны со смещениями соотношением (в обозначениях системы MATLAB):
![]() , (3.5)
, (3.5)
то из этого следует, что смещение для нейрона-победителя уменьшится, а смещения для остальных нейронов немного увеличатся.
М-функция learnсon использует следующую формулу для расчета приращений вектора смещений:
Страницы: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
