

 Доклад: Параллельные машины баз данных
Доклад: Параллельные машины баз данных
Четвертая проблема связана с обеспечением высокой готовности данных: система должна восстанавливать потерянные данные таким образом, чтобы это было “не очень” заметно для пользователя, выполняющего запросы к базе данных. Если в процессе восстановления 80-90% ресурсов системы тратится исключительно на цели восстановления базы данных, то такая система может оказаться неприемлемой для случаев, когда ответ на запрос должен быть получен немедленно.
Как мы увидим в дальнейшем, подходы к решению указанных проблем в определяющей степени зависят от аппаратной архитектуры параллельной машины баз данных.
Архитектура бывает разная
В 1986 г. М.Стоунбрейкер [8], предложил разбить архитектуры параллельных машин баз данных на три класса: архитектуры с разделяемой памятью и дисками, архитектуры с разделяемыми дисками и архитектуры без совместного использования ресурсов (рис.3).
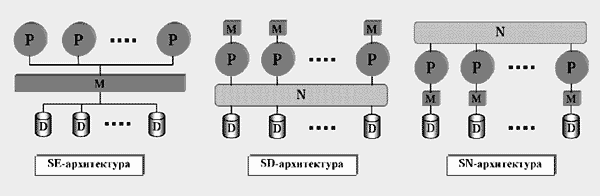
Рис.3. Три классические архитектуры: SE-архитектура с разделяемой памятью и дисками, SD-архитектура с разделяемыми дисками, SN-архитектура без совместного использования ресурсов. В SE-системах все процессоры P с помощью общей шины подключаются к разделяемой памяти M и дискам D. Процессоры передают друг другу данные через общую память. В SD-системах каждый процессор имеет свою собственную память, однако диски по-прежнему разделяются всеми процессорами. Для связи процессоров друг с другом используется высокоскоростная соединительная сеть N. В SN-системах каждый процессор имеет собственную память и собственный диск. Обмен данными между процессорами, как и в предыдущем случае, происходит через высокоскоростную соединительную сеть.
В системах с разделяемой памятью и дисками все процессоры при помощи общей шины соединяются с разделяемой памятью и дисками. Обозначим такую архитектуру как SE (Shared-Everything). В SE-системах межпроцессорные коммуникации могут быть реализованы очень эффективно через разделяемую память. Поскольку здесь каждому процессору доступны вся память и любой диск, проблема балансировки загрузки процессоров не вызывает принципиальных трудностей (простаивающий процессор можно легко переключить с одного диска на другой). В силу этого SE-системы демонстрируют для небольших конфигураций (не превышающих 20 процессоров) более высокую производительность по сравнению с остальными архитектурами.
Однако SE-архитектура имеет ряд недостатков, самые неприятные из которых - ограниченная масштабируемость и низкая аппаратная отказоустойчивость. При большом количестве процессоров здесь начинаются конфликты доступа к разделяемой памяти, что может привести к серьезной деградации общей производительности системы (поэтому масштабируемость реальных SE-систем ограничивается 20-30 процессорами). Не могут обеспечить такие системы и высокую готовность данных при отказах аппаратуры. Выход из строя практически любой аппаратной компоненты фатален для всей системы. Действительно, отказ модуля памяти, шины доступа к памяти или шины ввода-вывода выводит из строя систему в целом. Что касается дисков, то обеспечение высокой готовности данных требует дублирования одних и тех же данных на разных дисках. Однако поддержание идентичности всех копий может существенным образом снизить общую производительность SE-системы в силу ограниченной пропускной способности шины ввода-вывода. Все это исключает использование SE-архитектуры в чистом виде для систем с высокими требованиями к готовности данных.
В системах с разделяемыми дисками каждый процессор имеет свою собственную память. Процессоры соединяются друг с другом и с дисковыми подсистемами высокоскоростной соединительной сетью. При этом любой процессор имеет доступ к любому диску. Обозначим такую архитектуру как SD (Shared-Disk). SD-архитектура по сравнению с SE-архитектурой демонстрирует лучшую масштабируемость и более высокую степень отказоустойчивости. Однако при реализации SD-систем возникает ряд серьезных технических проблем, которые не имеют эффективного решения. По мнению большинства специалистов, сегодня нет весомых причин для поддержки SD-архитектуры в чистом виде.
В системах без совместного использования ресурсов каждый процессор имеет собственную память и собственный диск. Процессоры соединяются друг с другом при помощи высокоскоростной соединительной сети. Обозначим такую архитектуру как SN (Shared-Nothing). SN-архитектура имеет наилучшие показатели по масштабируемости и отказоустойчивости. Но ничто не дается даром: основным ее недостатком становится сложность с обеспечением сбалансированной загрузки процессоров. Действительно, в SN-системе невозможно непосредственно переключить простаивающий процессор на обработку данных, хранящихся на “чужом” диске. Чтобы разгрузить некоторый процессорный узел, нам необходимо часть “необработанных” данных переместить по соединительной сети на другой, свободный узел. На практике это приводит к существенному падению общей эффективности системы из-за высокой стоимости пересылки больших объемов данных. Поэтому перекосы в распределении данных по процессорным узлам могут вызвать полную деградацию общей производительности SN-системы.
Иерархические архитектуры
Для преодоления недостатков, присущих SE- и SN-архитектурам, А.Бхайд в 1988 г. предложил рассматривать иерархические (гибридные) архитектуры [9], в которых SE-кластеры объединяются в единую SN-систему, как это показано на рис.4. SE-кластер представляет собой фактически самостоятельный мультипроцессор с разделяемой памятью и дисками. Между собой SE-кластеры соединяются с помощью высокоскоростной соединительной сети N. Обозначим такую архитектуру как CE (Clustered-Everything). Она обладает хорошей масштабируемостью, подобно SN-архитектуре, и позволяет достигать приемлемого баланса загрузки, подобно SE-архитектуре.
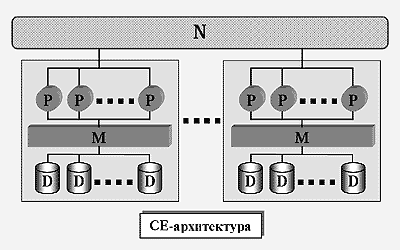
Рис.4. CE-архитектура. Эта система объединяет несколько SE-кластеров с помощью высокоскоростной соединительной сети. Каждый отдельный кластер фактически представляет собой самостоятельный мультипроцессор с SE-архитектурой.
Основные недостатки CE-архитектуры кроются в потенциальных трудностях с обеспечением готовности данных при отказах аппаратуры на уровне SE-кластера. Для предотвращения потери данных из-за отказов необходимо дублировать одни и те же данные на разных SE-кластерах. Однако поддержка идентичности различных копий одних и тех же данных требует пересылки по соединительной сети значительных объемов информации. А это может существенным образом снизить общую производительность системы в режиме нормального функционирования и привести к тому, что SE-кластеры станут работать с производительностью, как у однопроцессорных конфигураций.
Чтобы избавиться от указанных недостатков, мы предложили [10] альтернативную трехуровневую иерархическую архитектуру (рис.5), в основе которой лежит понятие SD2-кластера. Такой кластер состоит из несимметричных двухпроцессорных модулей PM с разделяемой памятью и набора дисков, объединенных по схеме SD. Обозначим данную архитектуру как CD2 (Clustered-Disk with 2-processor modules).
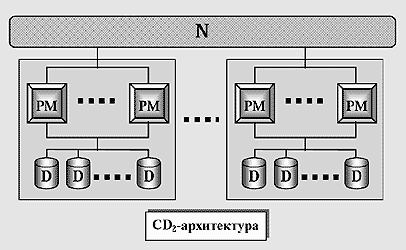
Рис.5. CD2-архитектура. Система строится как набор SD2-кластеров,
объединенных высокоскоростной соединительной сетью в стиле “без совместного
использования ресурсов”. Каждый кластер – это система с разделяемыми дисками и
двухпроцессорными модулями.
Структура процессорного модуля изображена на рис.6. Процессорный модуль имеет архитектуру с разделяемой памятью и включает в себя вычислительный и коммуникационный процессоры. Их взаимодействие осуществляется через общую оперативную память (RAM). Кроме этого, коммуникационный процессор имеет собственную память; он оснащен высокоскоростными внешними каналами (линками) для соединения с другими процессорными модулями. Его присутствие позволяет в значительной мере освободить вычислительный процессор от нагрузки, связанной с организацией передачи сообщений между процессорными узлами. Подобные процессорные модули выпускаются отечественной промышленностью для комплектования многопроцессорных вычислительных систем МВС-100/1000 [11].
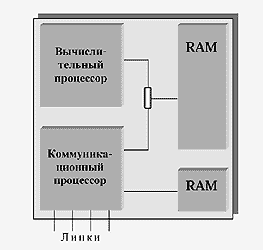
Рис.6. Несимметричный двухпроцессорный модуль с разделяемой памятью. Модуль оснащен двумя процессорами, взаимодействующими через разделяемую память (RAM). Коммуникационный процессор имеет приватную память и оснащен высокоскоростными каналами (линками) для связи с другими модулями.
Такую CD2-архитектуру мы использовали при реализации прототипа параллельной системы управления данными “Омега” для отечественных многопроцессорных комплексов МВС-100/1000. Как показали эксперименты, CD2-система способна достичь общей производительности, сравнимой с производительностью CE-системы, даже при наличии сильных перекосов в распределении данных по дискам. В то же время CD2-архитектура позволяет обеспечить более высокую готовность данных, чем CE-архитектура.
А добиться этого помогли новые алгоритмы размещения данных и балансировки загрузки.
Как устроена система “Омега”
Иерархическая архитектура системы “Омега” предполагает два уровня фрагментации. Каждое отношение разделяется на фрагменты, размещаемые в различных SD2-кластерах (межкластерная фрагментация). В свою очередь каждый такой фрагмент дробится на еще более мелкие части, распределяемые по различным узлам SD2-кластера (внутрикластерная фрагментация). Данный подход делает процесс балансировки загрузки более гибким, поскольку он может выполняться на двух уровнях: локальном, среди процессорных модулей внутри SD2-кластера, и глобальном, среди самих SD2-кластеров.
В системе “Омега” диски, принадлежащие одному кластеру, на логическом уровне делятся на непересекающиеся подмножества физических дисков, каждое из которых образует так называемый виртуальный диск. Количество виртуальных дисков в SD2-кластере постоянно и совпадает с количеством процессорных модулей. В простейшем случае одному виртуальному диску соответствует один физический диск. Таким образом, на логическом уровне SD2-кластер может рассматриваться как система с SN-архитектурой, в то время как физически это система с SD-архитектурой.
В основе алгоритма балансировки загрузки лежит механизм репликации данных, названный внутрикластерным дублированием. Его суть в том, что каждый фрагмент отношения дублируется на всех виртуальных дисках кластера (далее для простоты мы будем опускать термин “виртуальный”).
Схема работы предлагаемого алгоритма балансировки загрузки иллюстрируется на примере кластера с двумя процессорами (рис.7). Здесь процессору P1 сопоставлен диск D1, а процессору P2 - диск D2. Предположим, что нам необходимо выполнить некоторую операцию, аргументом которой является отношение R. Мы делим фрагменты, на которые разбито отношение R внутри SD2-кластера, на две примерно равные части. Первая часть назначается для обработки процессору P1, вторая - процессору P2 (на рис.7 данной стадии соответствует момент времени t0).
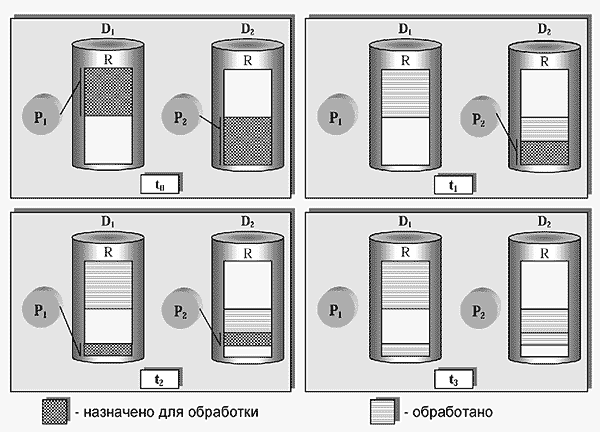
Рис.7. Алгоритм балансировки загрузки для кластера с двумя
процессорными узлами. На дисках D1 и D2
расположены две копии отношения R. Процессору P1 разрешен
доступ к копии, хранящейся на диске D1, а процессору P2
– к копии на D2. В начальный момент времени t0
фрагменты отношения R делятся между процессорами P1 и P2
примерно в равной пропорции. В момент времени t1 процессор P1
закончил обработку своей части отношения R, в то время как процессор P2 успел
выполнить только половину назначенной ему работы. В момент времени t2
происходит перераспределение необработанной части отношения R между двумя
процессорами. Перераспределение продолжается до тех пор, пока отношение R не
будет обработано полностью (момент времени t3).
В момент времени t1 процессор P1 закончил обработку своей части отношения R, в то время как процессор P2 успел выполнить только часть назначенной ему работы. В этом случае происходит повторное перераспределение необработанной части отношения R между двумя процессорами (момент времени t2 на рис.7). Процесс продолжается до тех пор, пока отношение R не будет полностью обработано (к моменту времени t3). Алгоритм очевидным образом обобщается на произвольное число процессоров.
Предложенный алгоритм балансировки загрузки процессоров позволяет избежать перемещения по соединительной сети больших объемов данных. Это в конечном счете и обеспечивает такой системе производительность, сравнимую с производительностью SE-кластеров даже при наличии сильных перекосов данных.
Подведем итоги
Очевидно, что параллельные машины баз данных с одноуровневой архитектурой на сегодняшний день практически уже исчерпали ресурс дальнейшего эффективного масштабирования. На смену им приходят новые системы с иерархической архитектурой, которые могут включать в себя на два порядка больше процессоров и дисков.
Однако при построении иерархических систем по двухуровневому принципу, когда кластеры процессоров с разделяемой памятью и дисками объединяются в единую систему “без совместного использования ресурсов”, возникает проблема обеспечения высокой готовности данных в случае отказов аппаратуры. Действительно, при большом количестве кластеров в системе вероятность отказа одного из кластеров становится достаточно большой, и нам необходимо дублировать одни и те же данные на нескольких различных кластерах, что по существу сводит на нет все преимущества иерархической организации.
Поэтому следует ожидать, что дальнейшее развитие иерархических архитектур параллельных машин баз данных пойдет по пути создания многоуровневых гибридных схем, способных обеспечить высокую готовность данных на конфигурациях с несколькими сотнями тысяч процессорных узлов. В качестве прототипа таких систем предлагается параллельная система баз данных “Омега”, разрабатываемая в Челябинском государственном университете, которая имеет трехуровневую иерархическую архитектуру типа CD2 и может включать в себя сотни SD2-кластеров. Но оптимальную архитектуру SD2-кластера еще предстоит найти. Мы планируем испытать различные конфигурации SD2-кластеров, варьируя топологию межпроцессорных соединений, количество процессорных модулей, количество дисковых подсистем и количество дисков у отдельной дисковой подсистемы.
Работа выполнена при поддержке Российского фонда фундаментальных исследований. Проект 00-07-90077.
Литература
1. Игнатович Н. // СУБД. 1997. №2. C.5-17.
2.Compaq NonStop SQL/MP. http://www.tandem.com/prod_des/nssqlpd/nssqlpd.htm
3. Лисянский К., Слободяников Д. // СУБД. 1997. №5-6. C.25-46.
4. Бернштейн Ф. и др. // Открытые системы. 1999. №1. C.61-68.
5. Кодд Е.Ф. // СУБД. 1995. №1. C.145-169.
6. Чамберлин Д.Д. и др. // СУБД. 1996. №1. C.144-159.
7. Девитт Д., Грэй Д. // СУБД. 1995. №2. C.8-31.
8. Stonebraker M. // Database Engineering Bulletin. March 1986. V.9. №1. P.4-9.
9. Bhide A. An Analysis of Three Transaction Processing Architectures // Proceedings of 14-th Internat. Conf. on Very Large Data Bases (VLDB'88), 29 August - 1 September 1988. Los Angeles, California, USA, 1988. P.339-350.
10.Sokolinsky L.B., Axenov O., Gutova S. Omega: The Highly Parallel Database System Project // Proceedings of the First East-European Symposium on Advances in Database and Information Systems (ADBIS’97), St.-Petersburg. September 2-5, 1997.V.2. P.88-90.
11.Левин В.К. Отечественные
суперкомпьютеры семейства МВС. http://parallel.ru/mvs/levin.html
