

 Реферат: Хеширование
Реферат: Хеширование
Частным случаем выбора константы является значение золотого сечения φ = (√5 - 1)/2 ≈ 0,6180339887. Если взять последовательность {φ}, {2φ}, {3φ},... где оператор { } возвращает дробную часть аргумента, то на отрезке [0..1] она будет распределена очень равномерно. Другими словами, каждое новое значение будет попадать в наибольший интервал. Это явление было впервые замечено Я. Одерфельдом (J. Oderfeld) и доказано С. Сверчковски (S. Świerczkowski) (см. [8]). В доказательстве играют важную роль числа Фибоначчи. Применительно к хешированию это значит, что если в качестве константы С выбрать золотое сечение, то функция будет достаточно хорошо рассеивать ключи вида {PART1, PART2, …, PARTN}. Такое хеширование называется хешированием Фибоначчи. Впрочем, существует ряд ключей (когда изменение происходит не в последней позиции), когда хеширование Фибоначчи оказывается не самым оптимальным [3].
Динамическое хеширование
Описанные выше методы хеширования являются статическими, т.е. сначала выделяется некая хеш-таблица, под ее размер подбираются константы для хеш-функции. К сожалению, это не подходит для задач, в которых размер базы данных меняется часто и значительно [9]. По мере роста базы данных можно
- пользоваться изначальной хеш-функцией, теряя производительность из-за роста коллизий;
- выбрать хеш-функцию «с запасом», что повлечет неоправданные потери дискового пространства;
- периодически менять функцию, пересчитывать все адреса. Это отнимает очень много ресурсов и выводит из строя базу на некоторое время.
Существует техника, позволяющая динамически менять размер хеш-структуры [10]. Это – динамическое хеширование. Хеш-функция генерирует так называемый псевдоключ (“pseudokey”), который используется лишь частично для доступа к элементу. Другими словами, генерируется достаточно длинная битовая последовательность, которая должна быть достаточна для адресации всех потенциально возможных элементов. В то время, как при статическом хешировании потребовалась бы очень большая таблица (которая обычно хранится в оперативной памяти для ускорения доступа), здесь размер занятой памяти прямо пропорционален количеству элементов в базе данных. Каждая запись в таблице хранится не отдельно, а в каком-то блоке (“bucket”). Эти блоки совпадают с физическими блоками на устройстве хранения данных. Если в блоке нет больше места, чтобы вместить запись, то блок делится на два, а на его место ставится указатель на два новых блока.
Задача состоит в том, чтобы построить бинарное дерево, на концах ветвей которого были бы указатели на блоки, а навигация осуществлялась бы на основе псевдоключа. Узлы дерева могут быть двух видов: узлы, которые показывают на другие узлы или узлы, которые показывают на блоки. Например, пусть узел имеет такой вид, если он показывает на блок:
| Zero | Null |
| Bucket | Указатель |
| One | Null |
Если же он будет показывать на два других узла, то он будет иметь такой вид:
| Zero | Адрес a |
| Bucket | Null |
| One | Адрес b |
Вначале имеется только указатель на динамически выделенный пустой блок. При добавлении элемента вычисляется псевдоключ, и его биты поочередно используются для определения местоположения блока. Например (см. рисунок), элементы с псевдоключами 00… будут помещены в блок A, а 01… - в блок B. Когда А будет переполнен, он будет разбит таким образом, что элементы 000… и 001… будут размещены в разных блоках.
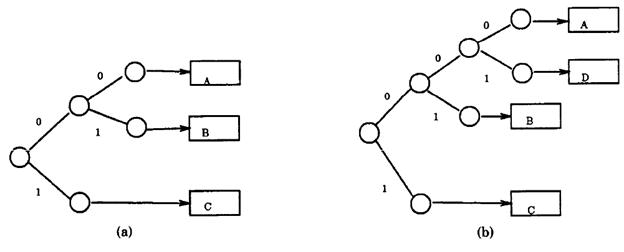
Расширяемое хеширование (extendible hashing)
Расширяемое хеширование близко к динамическому. Этот метод также предусматривает изменение размеров блоков по мере роста базы данных, но это компенсируется оптимальным использованием места. Т.к. за один раз разбивается не более одного блока, накладные расходы достаточно малы [9].
Вместо бинарного дерева расширяемое хеширование предусматривает список, элементы которого ссылаются на блоки. Сами же элементы адресуются по некоторому количеству i битов псевдоключа (см. рис). При поиске берется i битов псевдоключа и через список (directory) находится адрес искомого блока. Добавление элементов производится сложнее. Сначала выполняется процедура, аналогичная поиску. Если блок неполон, добавляется запись в него и в базу данных. Если блок заполнен, он разбивается на два, записи перераспределяются по описанному выше алгоритму. В этом случае возможно увеличение числа бит, необходимых для адресации. В этом случае размер списка удваивается и каждому вновь созданному элементу присваивается указатель, который содержит его родитель. Таким образом, возможна ситуация, когда несколько элементов показывают на один и тот же блок. Следует заметить, что за одну операцию вставки пересчитываются значения не более, чем одного блока. Удаление производится по такому же алгоритму, только наоборот. Блоки, соответственно, могут быть склеены, а список – уменьшен в два раза.
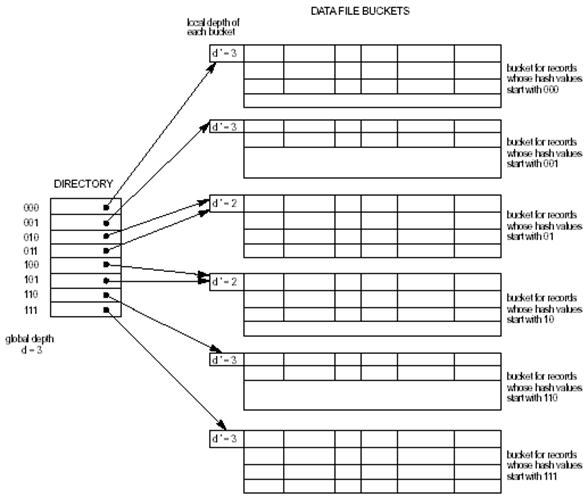
Итак, основным достоинством расширяемого хеширования является высокая эффективность, которая не падает при увеличении размера базы данных. Кроме этого, разумно расходуется место на устройстве хранения данных, т.к. блоки выделяются только под реально существующие данные, а список указателей на блоки имеет размеры, минимально необходимые для адресации данного количества блоков. За эти преимущества разработчик расплачивается дополнительным усложнением программного кода.
Функции, сохраняющие порядок ключей (Order preserving hash functions)
Существует класс хеш-функций, которые сохраняют порядок ключей [11]. Другими словами, выполняется
K1 < K2 à h(K1) < h(K2)
Эти функции полезны для сортировки, которая не потребует никакой дополнительной работы. Другими словами, мы избежим множества сравнений, т.к. для того, чтобы отсортировать объекты по возрастанию достаточно просто линейно просканировать хеш-таблицу.
В принципе, всегда можно создать такую функцию, при условии, что хеш-таблица больше, чем пространство ключей. Однако, задача поиска правильной хеш-функции нетривиальна. Разумеется, она очень сильно зависит от конкретной задачи. Кроме того, подобное ограничение на хеш-функцию может пагубно сказаться на ее производительности. Поэтому часто прибегают к индексированию вместо поиска подобной хеш-функции, если только заранее не известно, что операция последовательной выборки будет частой.
Минимальное идеальное хеширование
Как уже упоминалось выше, идеальная хеш-функция должна быстро работать и минимизировать число коллизий. Назовем такую функцию идеальной (perfect hash function) [12]. С такой функцией можно было бы не пользоваться механизмом разрешения коллизий, т.к. каждый запрос был бы удачным. Но можно наложить еще одно условие: хеш-функция должна заполнять хеш-таблицу без пробелов. Такая функция будет называться минимальной идеальной хеш-функцией. Это идеальный случай с точки зрения потребления памяти и скорости работы. Очевидно, что поиск таких функций – очень нетривиальная задача.
Один из алгоритмов для поиска идеальных хеш-функций был предложен Р. Чичелли [13]. Рассмотрим набор некоторых слов, для которых надо составить минимальную идеальную хеш-функцию. Пусть это будут некоторые ключевые слова языка С++. Пусть это будет какая-то функция, которая зависит от некоего численного кода каждого символа, его позиции и длины. Тогда задача создания функции сведется к созданию таблицы кодов символов, таких, чтобы функция была минимальной и идеальной. Алгоритм очень прост, но занимает очень много времени для работы. Производится полный перебор всех значений в таблице с откатом назад в случае необходимости, с целью подобрать все значения так, чтобы не было коллизий. Если взять для простоты функцию, которая складывает коды первого и последнего символа с длиной слова (да, среди слов умышленно нет таких, которые дают коллизию), то алгоритм дает следующий результат:
| Буква | Код | Буква | Код | Буква | Код | Буква | Код | Буква | Код |
| a | -5 | e | 4 | i | 2 | n | -1 | t | 10 |
| b | -8 | f | 12 | k | 31 | o | 22 | u | 26 |
| c | -7 | g | -7 | l | 29 | r | 5 | v | 19 |
| d | -10 | h | 4 | m | -4 | s | 7 | w | 2 |
| Слово | Хеш | Слово | Хеш | Слово | Хеш | Слово | Хеш |
| Auto | 21 | Double | 0 | Int | 15 | Struct | 23 |
| Break | 28 | Else | 12 | Long | 26 | Switch | 17 |
| Case | 1 | Enum | 4 | Register | 18 | Typedef | 29 |
| Char | 2 | Extern | 9 | Return | 10 | Union | 30 |
| Const | 8 | Float | 27 | Short | 22 | Unsigned | 24 |
| Continue | 5 | For | 20 | Signed | 3 | Void | 13 |
| Default | 7 | Goto | 19 | Sizeof | 25 | Volatile | 31 |
| Do | 14 | If | 16 | Static | 6 | While | 11 |
Подробный анализ алгоритма, а также реализацию на С++ можно найти по адресу [12]. Там же описываются методы разрешения коллизий. К сожалению, эта тема выходит за рамки этой работы.
