

 Реферат: Архитектура IA-32
Реферат: Архитектура IA-32
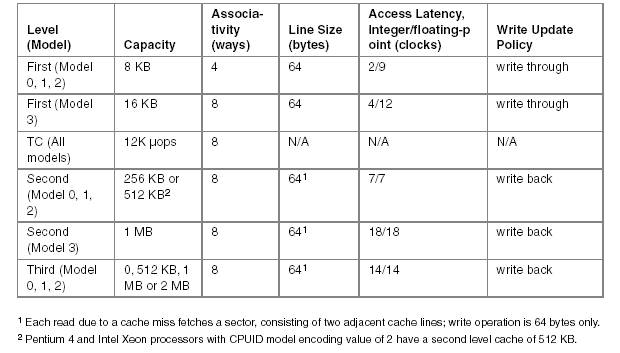
На процессорах без КЭШа третьего уровня, промах КЭШа второго уровня инициирует транзакцию через интерфейс системной шины в подсистему памяти. На процессорах с тремя уровнями КЭШа, промах КЭШа третьего уровня инициирует транзакцию через системную шину. Транзакция записи через шину записывает 64 байта в кэшируемую память, или раздельные восьми байтные контейнеры, если место назначения не кэшируется. Транзакция чтения через шину из кэшируемой памяти извлекает две нити данных КЭШа.
Интерфейс системной шины поддерживает работу с масштабируемой частотой шины и достигает эффективной скорости в четыре раза превышающей скорость шины. Маршрут от входа в шину и обратно занимает двенадцать процессорных циклов, и от шести до двенадцати циклов для доступа к памяти, если шина не перегружена. Каждый цикл шины соответствует нескольким циклам процессора. Отношение тактовой частоты процессора к масштабируемой тактовой частоте системной шины, если один цикл шины. Например, один цикл шины с частотой 100 МГц эквивалентен пятнадцати циклом процессора в 1,5 ГГц процессоре.
Предвыборка данных
Процессоры Intel Xeon и Pentium 4 имеют два механизма предвыборки данных: программно управляемая предвыборка и автоматическая аппаратная предвыборка.
Программно управляемая предвыборка включается с помощью четырех инструкций предвыборки (PREFETCHh) представленных в SSE. Программно управляемая предвыборка не обязательна для предвыборки кодов. Ее использование может привести к большим проблемам в многопроцессорных системах, если код разделен между процессорами.
Программно управляемая предвыборка данных может принести выгоду в следующих ситуациях:
· когда блок команд доступа к памяти в приложении позволяет программисту перекрыть задержки доступа к памяти
· когда точный выбор может быть сделан, основываясь на знании количества нитей кэша к выбору в дальнейшем перед исполнением текущей нити
· когда выбор может быть сделан, основываясь на знании того, какую предвыборку необходимо использовать
Инструкции предвыборки SSE имеют различные характеры поведения в зависимости от уровня кэша и реализации процессора. Например, в процессоре может быть реализована постоянная предвыборка, путем возврата данных в уровень кэша, ближайший к ядру процессора. Такой метод приводит к следующему:
· минимизирует нарушения временных данных в других уровнях кэша
· предупреждает необходимость доступа к внекристальным КЭШам, что может увеличить реализованную мощность относительно неправильной загрузки, которая перегружает данные во все уровни кэша
Ситуации, в которых не желательно использовать программно управляемую предвыборку:
· в случаях, когда запросы определены, предвыборка приводит к увеличению требований запросов
· в случае предвыборки далеко вперед, она может привести к вытеснению кэшированных данных из кэша раньше, чем они будут использованы
· слишком близкая предвыборка может снизить возможность к перекрытию задержек доступа к памяти и выполнения
Программные предвыборки потребляют ресурсы в процессоре, и использование слишком многих предвыборок может ограничить их эффективность. Примеры таких предвыборок включают предвыборку данных в цикле для не зависимости от информации находящейся вне цикла и предвыборку в основных блоках, которые часто исполняются, но которые редко используют ее не зависимо от целей предвыборки.
Автоматическая аппаратная предвыборка – механизм, реализованный в процессорах Intel Xeon и Intel Pentium 4. Она заносит нити кэша в унифицированный кэш второго уровня, основанный на ранних независимых моделях.
Плюсы и минусы программной и аппаратной предвыборки
Программная предвыборка имеет следующие характеристики:
· обрабатывает необычные модели доступа, которые не перехватываются аппаратным предвыборщиком
· обрабатывает предвыборку коротких массивов и не имеет аппаратной начальной задержки перед инициацией выборок
· должна быть добавлена в каждый новый код, так что она не относится к уже запущенным приложениям
Аппаратная предвыборка имеет следующие характеристики:
· работает с уже существующими приложениями
· не требует хорошего знания инструкций предвыборки
· требует постоянных моделей доступа
· предупреждает перегрузку инструкций и выводных портов
· имеет начальную задержку на настройку аппаратного предвыборщика и начало инициации выборок
Аппаратный предвыборщик может обрабатывать множество потоков, как в прямом, так и в обратном направлении. Начальная задержка и «выборка-на-перед» имеет больший эффект на коротких массивах, когда аппаратная предвыборка генерирует запрос на данные уже в конце обработки массива (вообще-то в этих случаях она даже не начинается). Аппаратная задержка уменьшается при обработке более длинных массивов.
Загрузка и хранение
В процессорах Intel Xeon и Pentium 4 реализованы следующие механизмы увеличения скорости обработки операций с памятью:
· спекулятивное выполнение загрузок
· реорганизация загрузок с учетом загрузок и хранений
· буферизация записей
· управление потоком данных из хранилищ в зависимые загрузки
производительность может быть увеличена не с помощью ширины канала вывода памяти, а буферизацией ресурсов предоставляемых процессором. По одной операции загрузки и хранения может быть выдано из станции резервирования портов памяти за цикл. Для того, чтобы быть помещенной в станцию хранения, для каждой операции с памятью должен быть доступен буферизированный вход. Имеются 48 загрузочных и 24 хранящих буфера. Эти буфера содержат микрокоманды и адресную информацию до тех пор, пока операция не выполнена, извлечена и перемещена.
Процессоры Intel Pentium 4 и Intel Xeon спроектированы для исполнения операций памяти в беспорядочном режиме относительно других инструкций и относительно друг друга. Загрузки могут выполняться спекулятивно, то есть до того как найдены результаты всех ветвлений. Несмотря на это, спекулятивные загрузки не могут вызвать ошибку страницы.
Реорганизация загрузок относительно друг друга может предотвратить не верную загрузку из более поздних (предсказанных). Реорганизация загрузок относительно других загрузок и хранилищ по различным адресам позволяет больше параллелизма, что в свою очередь позволяет машине выполнять операции, как только готовы их входные данные. Запись в память всегда выполняется спекулятивно в оригинальном порядке для исключения ошибок.
Промах кэша для загрузки не предотвращает другие загрузки от выдачи и завершения. Процессоры Intel Xeon и поддерживают до 4 (8 для Intel Xeon и Pentium 4 с сигнатурой CPUID относящихся к семейству 15, модели 3) исключительных промаха загрузки, произведенных, как кэшем в кристалле, так и памятью.
Хранящие буфера улучшают производительность, позволяя процессору продолжать выполнение инструкций, не задерживаясь пока запись в кэш или память будет завершена. Запись обычно не производиться на практических путях зависимых цепочек, так что обычно лучше отложить запись для более эффективного использования памяти.
Управление хранением
Загрузка может быть сдвинута относительно хранения, если не предсказано загружать по тому же линейному адресу, что и хранение. Если они действительно производят чтение по тому же линейному адресу, они должны дождаться пока сохраненные данные не станут доступными. Несмотря на это, им не требуется ждать, пока хранилище сделает запись в иерархию памяти и закончит работу. Данные из хранилища могут быть направлены напрямую, если выполняются следующие условия:
· Очередность: данные, направляемые в загрузку, сгенерированы программно ранее выполненным хранением
· Размерность: загружаемые байты должны бать подмножеством (включая правильное подмножество, что одно и то же) байтов хранилища
· Выравнивание: хранилище не может вращаться внутри границ нити кэша, и линейный адрес загрузки должен быть идентичен адресу хранилища
Технология Hyper-Threading
Технология Intel Hyper-Threading (HT) поддерживается специфичными членами семейств Intel Xeon (Nocona) и Intel Pentium (Prescott). Технология позволяет приложениям пользоваться преимуществами параллелизма, представляемыми на уровне заданий или потоков несколькими логическими процессорами внутри одного физического. В своей первой реализации в процессоре Intel Xeon, НТ представляла один физический процессор как два логических. Эти два логических процессора имеют полный набор архитектурных регистров, разделяя ресурсы одного физического процессора. Имея архитектуру двух процессоров, НТ встроенная в процессор выглядит как два процессора для приложений, операционных систем и программного кода.
При помощи распределения ресурсов, при пиковых запросах, между двумя логическими процессорами, НТ хорошо подходит для многопроцессорных систем, производя дополнительное увеличение мощности по сравнению с обычными многопроцессорными системами.
Рисунок 6 показывает типичную шинно-основанную симметричную многопроцессорную систему (SMP), основанную на процессорах поддерживающих технологию НТ. Каждый логический процессор может выполнять программный поток, позволяя двум потокам выполняться одновременно в одном физическом процессоре.
В технологии НТ физические ресурсы делятся, а архитектурная модель дублируется для каждого логического процессора. Это минимизирует потери от мертвых зон, при достижении целей много потоковых приложений или многозадачных платформ.
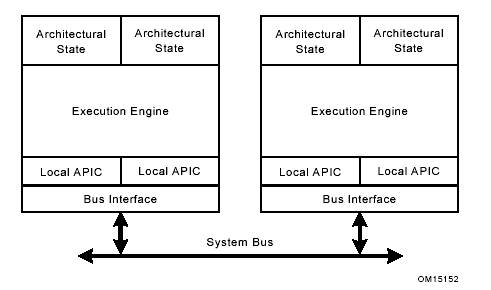
Рисунок 5. Технология Hyper-Threading на SMP
Производительный потенциал НТ основывается:
· на факте, что операционная система и пользовательские приложения могут закреплять потоки или процессы за логическими процессорами каждого из физических процессоров.
· Возможности к использованию исполнительных ресурсов кристалла на более высоком уровне, чем когда один поток потребляет все исполнительные ресурсы
Ресурсы процессора и технология Hyper-Threading
Большинство микроархитектурных ресурсов физического процессора делятся между логическими процессорами. Только некоторые небольшие структуры данных дублируются для каждого логического процессора. В этом разделе описывается, как ресурсы разделяются, делятся или реплицируются.
Реплицированные ресурсы
Архитектурная модель дублируются для каждого логического процессора. Архитектурная модель состоит из регистров используемых операционной системой и программного кода контролирующего взаимодействие программ и хранение данных для вычислений. Эта модель включает восемь регистров специального назначения, контролирующие регистры, регистры отладки и т.д. За исключением MTRRs – регистров (memory type range registers) и ресурсов мониторинга за производительностью
Остальные ресурсы, такие как указатели инструкций, таблицы переименований регистров, реплицируются для одновременного слежения за выполнением и изменениями в логических процессорах. Предсказатель стека возвратов реплицируется для улучшения предсказания ветвлений инструкций возврата.
В дополнение реплицируются несколько буферов (например, двух входные буферы потоковых инструкций), для снижения нагрузки.
Разделенные ресурсы
Несколько буферов делятся пополам между процессорами. Они относятся к разделенным ресурсам. Причины этого деления:
· Операционная равнодоступность
· Возможность операций одного логического процессора не зависеть от зависших операций другого логического процессора
Промах кэша, неверное предсказание ветвления или зависимости инструкций могут помешать логическому процессору работать на полной мощности в течение некоторого числа циклов. Разделение предотвращает зависший логический процессор от блокирования.
Главное, буфера инструкций очередей для главного конвейера делятся между процессорами. Эти буфера включают очереди микрокоманд после исполнительного кэша трасс, очереди после стадии переименования регистра, разупорядочивающий буфер, который хранит очередь инструкций для изъятия и загрузочные и хранящие буфера.
В случае буферов загрузки и хранения, деление так же производиться в легком варианте, для получения реорганизации памяти для каждого логического процессора и для определения ошибок организации памяти.
Разделяемые ресурсы
Большинство ресурсов в физическом процессоре полностью разделяются для улучшения динамического использования ресурсов, включая кэши и все исполнительные блоки. Некоторые разделяемые ресурсы, адресованные линейно, например DTLB, включают бит идентификации логического процессора, для определения какому логическому процессору принадлежит информацию.
Микроархитектура конвейера и технология НТ
В этой части описывается микроархитектура НТ, и как инструкции из двух логических процессоров распределяются между блоком начальной и конечной загрузки конвейера.
Так как инструкции, передаваемые из двух программ или процессов, выполняются одновременно, нет необходимости в жестком программном порядке в исполнительном ядре и иерархии памяти, блоки начальной и конечной загрузки содержат несколько выборных точек для выбора между инструкциями из двух логических процессоров. Все выборные точки работают между двумя логическими процессорами, за исключением случаев, когда один из логических процессоров не может использовать текущее состояние конвейера. В этом случае другой логический процессор использует каждый цикл конвейер в полном объеме. Причины, по которым один из логических процессоров не может использовать конвейер – это промахи загрузки кэша, не верное предсказание ветвлений и зависимость инструкций.
Блок начальной загрузки конвейера
Исполнительный кэш трасс разделяется между двумя логическими процессорами. Доступ к исполнительному кэшу трасс произвольно делиться между двумя логическими процессорами каждый такт. Если нить кэша выбрана для одного логического процессора в одном цикле, в следующем цикле нить будет выбрана для другого логического процессора. Таким образом, оба логических процессора запрашивают доступ к кэшу трасс.
Если один логический процессор зависает или не может использовать исполнительный кэш трасс, другой будет использовать кэш трасс на всю мощность до тех пор, пока инструкция инициации логического процессора не выдаст ему команду возврата из кэша второго уровня.
После выборки инструкций и построения трасс микрокоманд, они ставятся в очередь. Эта очередь разделяет кэш трасс, начиная с блока переименования регистров конвейера. Как было описано выше, если оба логических процессора активны, очередь делиться, так что оба процессора могут обрабатывать информацию независимо.
Исполнительное ядро
Ядро может выдавать до шести микрокоманд за цикл, готовых к исполнению. Как только микрокоманда помещена в очередь, ожидая выполнения, нет разницы между тем из какого процессора пришла эта инструкция. Исполнительному ядру и иерархии памяти так же безразлично, к какому процессору принадлежат инструкции.
После исполнения, инструкции помещаются в переупорядочивающий буфер. Переупорядочивающий буфер разделяет исполнительную стадию от стадии извлечения. Переупорядочивающий буфер делиться так, что каждый логический процессор использует половину входов.
Извлечение
Логика извлечений следит, когда инструкции из двух логических процессоров готовы к извлечению. Она извлекает инструкции в программном порядке для каждого логического процессора по очереди. Если один из логических процессоров не готов к извлечению любой инструкции, все изъятые инструкции направляются в другой процессор.
Как только информация извлечена из хранилища, процессору необходимо записать хранимые данные в кэш данных первого уровня. Выборочная логика чередуется между двумя логическими процессорами для передачи хранимых данных в кэш.
Список использованной литературы
1. IA-32 Intel® Architecture Optimization Reference Manual
2. www.intel.com
3. www.iXTB.com
4. www.allintel.ru
